How to Get Started With Technical SEO?
And learn of how to have a "technically" better website for Search Engines.

SEO (or Search Engine Optimization) is probably one of my favorite acquisition channels for growth. It's also one of the marketing channels that requires a lot of upfront work before you start seeing any results.
But on the other side, it's also a channel that doesn’t get enough attention all the time (usually disregarded by teams who believe "paid" is the only way) or confused with quick keyword/backlink hacks that shoot to the #1 position in Google.
So, I’ve decided to create a deep dive into Technical SEO, one of the most crucial components in your whole SEO strategy. I believe this is a foundational area, where you can figure out how Google works and how the different technical components can impact your website, before you even start producing content/links.
Who can benefit from this guide?
Teams who want to start with SEO or have a very basic foundation.
Product & Engineering teams, who knows Technical SEO is important, but don`t have in-house specialist to guide them.
Teams who have SEO implemented, but want to double-check if they are not missing something.
SEO specialists who want to rewind their knowledge (and maybe learn something new).
What is the definition of Technical SEO?
Technical SEO refers to optimizing the technical aspects of a website to improve its ranking in search engines. It's about making a website faster, easier to crawl, and understandable for search engines. The main goal is to enhance the user experience and adhere to search engine guidelines to drive more organic traffic. Unlike other SEO forms focused more on content and link building, technical SEO concentrates on the infrastructure of your website.
Why is important to work on Technical SEO and who should be involved?
For search engines like Google, being able to crawl and index your webpages fast and efficiently is the most important task in order to provide relevant results for all search queries.
The crawlers are the main "workers" for every search engine, and their job is to parse & render a webpage, get the context of what it is about, and move to the next one.
They have limited time to crawl a website and every major blocker for them, usually is associated with your page “not being indexed”.
So, as a business if you rely on SEO to drive free traffic, convert users and build up revenue, wouldn’t you want your website health to be in top shape?
You’ve written an amazing long-form guide that can drive XX,XXX of users, but your page has wrong "robots meta tags," not allowing crawlers to crawl and index your webpage.
That’s why focusing on Technical SEO first is usually the place where I advise teams to focus on. No matter the size of your business, you should never skip or delay solving technical challenges first.
If you are a small company, usually your website is built on CMS (WordPress, etc.) and changes there can be made pretty fast. If you are lacking engineers, you can always contract one and solve all your issues with your internal SEO member. Or, if you don’t have even an SEO person, you can pick up some basic learnings online or use a guide like this one.
If you are a medium to big size company, usually you have already a tech team and marketing team. Of course, the complication here comes from having a more complex tech stack, more systems, and different teams utilizing web assets. That's why it is important to have technical SEO modules implementation as a cross-collaboration between different stakeholders.
In the next point, we will dive deeper into how search engines render a page (Google in particular) and the most important areas to work on.
Before we dive into the specific components, it's important to understand first how Google crawls, renders, and indexes a webpage. This is not a must-know for a regular SEO person, but it gives you a perspective that having a good webpage is more than content and links.
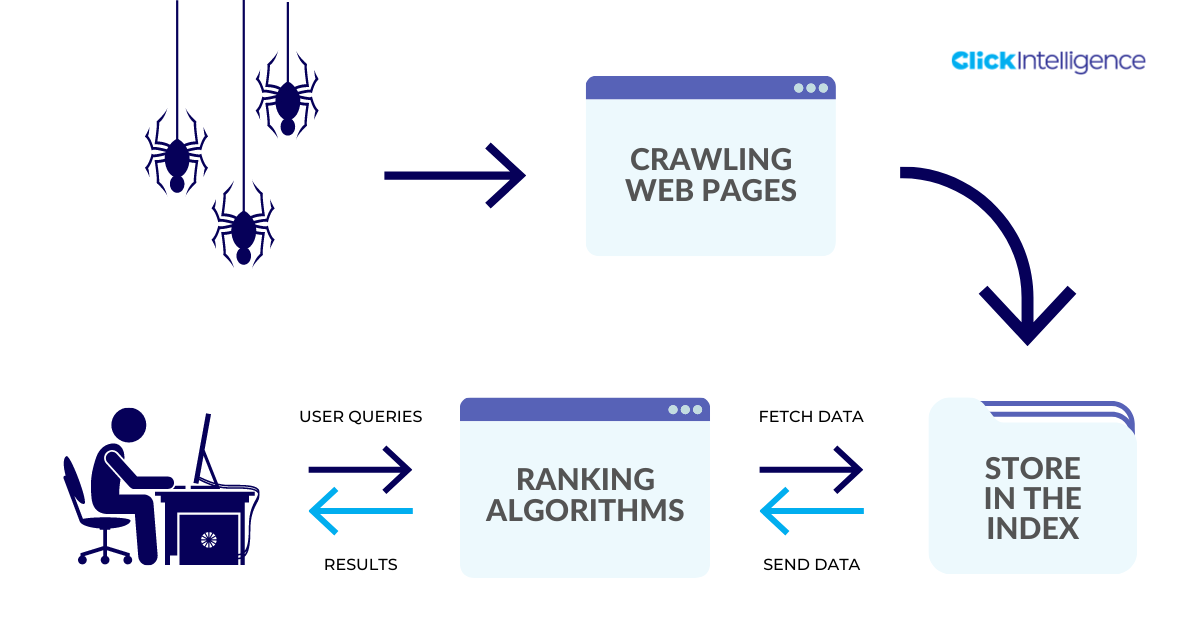
What does it mean for your webpage to be crawled, indexed, and ranked in Google?
In simple language, it's a process where web crawlers discover your page (where Technical SEO is key), Google stores that page in their index (think of it as a massive library), then Google has predefined ranking algorithms that give weight to your webpage (speed, robots, sitemap, canonical, links, content, mobile-friendly, etc.) and decide where it will rank each time a user performs a query search on the front-end.
What means content rendering?
A web browser engine is like a translator that turns code and media from websites (like text and images) into the visual web pages we see. It uses specific rules (like CSS for style) to decide how everything looks and fits together on the page. Some engines wait until they have all the information to show you the complete page, while others start showing you parts of the page as they get the information.
The picture below illustrates a high-level workflow of the browser.

Different browsers use different rendering engines
Firefox uses Gecko
Safari uses WebKit
Chrome & Opera ( from version 15 ) use Blink, which is a fork of WebKit.
Lets look a more detailed breakdown for WebKit and Gecko content rendering engines main flow
WebKit

Gecko

What Are the Components of Technical SEO?
I will focus here primary on the most important one in my opinion and the one with highest impact on your webpages.
Robots.txt File
What it is?
It`s a file used to instruct web robots (typically search engine robots) about how to crawl pages on their website.
What is the functionality?
The robots.txt file tells the crawler which parts of the site are restricted and should not be processed or included in their index. For instance, it can block access to private, duplicate content, or enable strict folder indexing for .css or .js files, for example. Here's a basic sample of how it looks, how to structure it, and how to block/unblock, including samples from WordPress and other crawlers.

Where is located?
The file can be found in the root directory ( www.example.com/robots.txt ). Usually, this is the first place crawlers looks before navigating through the site.
I would strongly advise to keep the file in that directly location for discovery reasons.
How important it is?
Its quite important as a file to get it done the right way, as it helps manage crawler traffic and ensure only desired content is indexed.
Tips for building it?
Be sure, to double-check always with engineers if there are not important files in every directory you want to block.
Don`t try to block every single file or directory. Sometimes, keep it more simple its better.
Don`t block with robots.txt your JavaScript or CSS files. Let the crawler access it, as it needs them to render the page.
Be sure to check different CMS and their file structure, as one 1 rule doesn’t apply across all.
Avoid using it to hide sensitive data (as it doesn't provide security).

Sitemap.xml File
What it is?
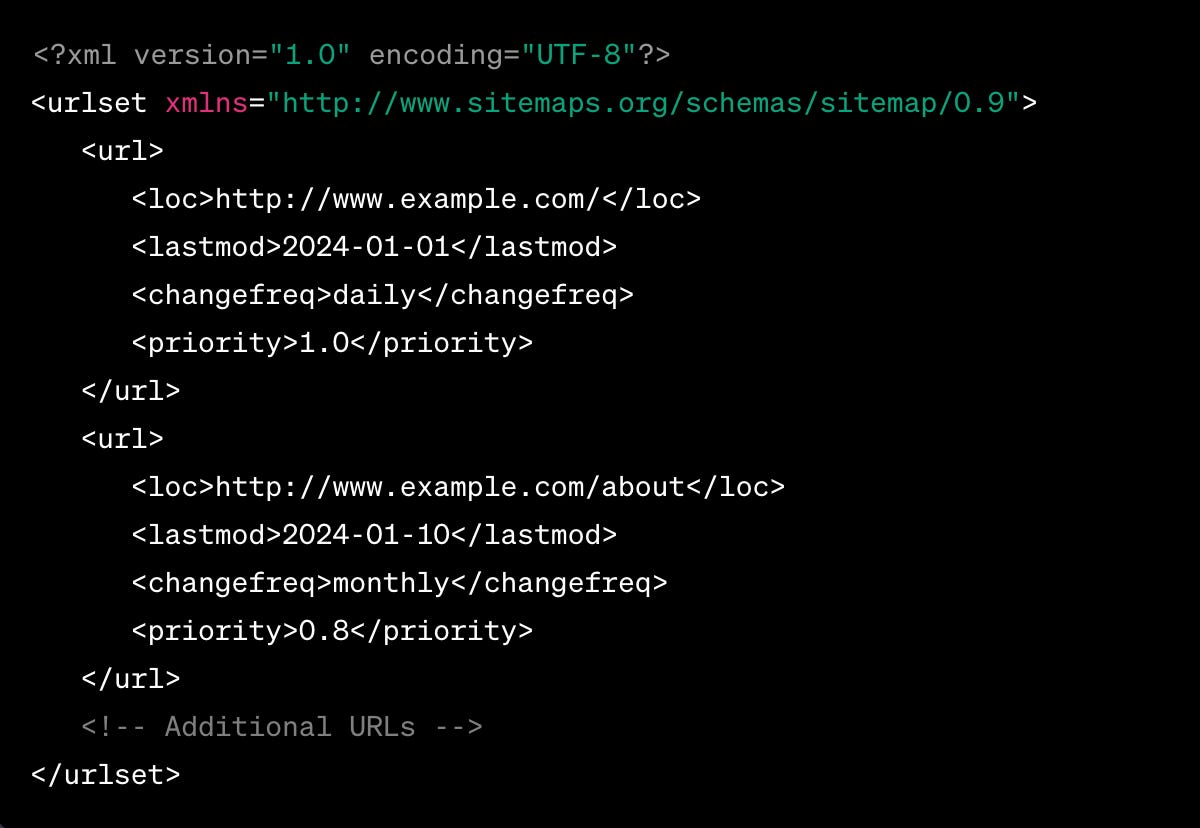
A “sitemap.xml” file is used by website owners to inform search engines about the pages on their website that are available for crawling. It acts like a map of your website, showing search engines all the accessible pages.
What is the functionality?
The sitemap helps search engines to better crawl your website. It lists the URLs of a site along with additional metadata about each URL (like when it was last updated, how often it changes, and how important it is in relation to other URLs on the site) to ensure more intelligent crawling by search engines.
Ex.

Where is located?
This file is typically located in the root directory of your website, similar to the robots.txt file. For ex, you can find it at ( www.example.com/sitemap.xml ). Having it in the root directory makes it easy for search engines to find and use it.
How important it is?
A sitemap is particularly important for larger websites with many pages, new websites with few external links, or sites with rich media content. It ensures that search engines can find and index all your important pages, potentially improving your site’s visibility in search results.
Tips for building it?
Include only canonical URLs to avoid duplicate content issues.
Regularly update your sitemap with new or updated pages.
Prioritize your pages: make sure the most important and frequently updated pages are listed.
Keep the XML file format clean and follow the standard protocol.
For large websites, consider splitting the sitemap into multiple files and use a sitemap index file.
Validate your sitemap with tools to check for errors.
Canonical tag
What it is?
The canonical tag is an HTML element that helps webmasters prevent duplicate content issues in SEO by specifying the "canonical" or "preferred" version of a web page. It's part of the head section of the HTML document.
What is the functionality?
The tag tells search engines which version of a URL you want to appear in search results. This is especially important when similar or identical content exists on multiple URLs. By using the canonical tag, you can point search engines to the original page, helping to consolidate ranking signals and prevent confusion over content duplication.
Where is located?
The canonical tag is placed within the
<head>section of the HTML code of a web page. Each page that has duplicate or similar content should contain a canonical tag pointing to the preferred URL.
How important it is?
It is crucial for managing SEO effectively, especially for websites that have similar or duplicate content across multiple URLs. Proper use of the canonical tag helps improve site ranking by ensuring that search engines index and rank the most relevant and original page
Tips for building it?
Ensure that the canonical URL is the definitive version you want search engines to index.
Be consistent: the URL in the canonical tag should match exactly the preferred URL.
Use absolute URLs (including the http:// or https://) in your canonical tags.
Avoid using canonical tags to point to totally different pages, as this can be seen as misleading.
Regularly audit your canonical tags to ensure they are pointing to the correct URLs and are used correctly across your website.

Robots Meta Tag
What it is?
The robots meta tag is an HTML tag used to instruct search engines on how to crawl and index pages on a website. It provides more granular control than the robots.txt file, as it is applied on a page-by-page basis.
What is the functionality?
This tag tells search engines whether they should index a page and follow the links on it. It offers options like "noindex" (don’t index this page), "nofollow" (don’t follow links on this page), "noarchive" (don’t save a cached copy of this page), among others. It helps in controlling the search engine behavior regarding specific pages.
Where is located?
The robots meta tag is placed within the
<head>section of the HTML code of each individual web page where you want to apply specific crawling and indexing instructions.
How important it is?
It is very important for SEO and overall website management. By using the robots meta tag, you can prevent search engines from indexing duplicate, private, or irrelevant pages. This ensures that only the most valuable and relevant content appears in search engine results, enhancing the effectiveness of your SEO strategy.
Tips for building it?
Use the tag judiciously: only apply it to pages that you specifically want to control search engine access to.
Be clear about the directives: understand the difference between 'noindex', 'nofollow', and other directives.
Regularly review your usage of the tag to ensure it aligns with your current SEO strategy.
Remember that the robots meta tag overrides directives set in the robots.txt file.
Use the "noindex, follow" directive for pages that should not be indexed but can pass link equity to other pages.

Server redirects
What is it?
Server redirects are methods used by web servers to forward visitors from one web page URL to another. This is typically done to direct traffic from old or deleted pages to new or relevant ones, or from non-www to www versions of a site (or vice versa).
What is the functionality?
The primary function of server redirects is to ensure a smooth user experience by guiding visitors to the correct page and to transfer SEO value from one URL to another. Common types include 301 (permanent) and 302 (temporary) redirects.
Where is located?
Server redirects are configured on the server-side, often within files like .htaccess for Apache servers, or web.config for Windows servers. They're not visible in the HTML code of a webpage like meta tags.
How important it is?
They are crucial for maintaining a website’s SEO health. Proper use of redirects can prevent 404 errors, improve user experience, and maintain or pass on the link equity (ranking power) to the new page.
Tips for building it?
Use 301 redirects for permanently moved pages to transfer SEO value.
Reserve 302 redirects for temporary changes, as they don’t pass on link equity.

Avoid redirect chains (multiple redirects in a row), as they can slow down site loading and dilute SEO value.
Ensure that redirects are implemented correctly to avoid common issues like redirect loops.
Impact on Load Time: Redirects can impact page load time, so minimize their use when possible.
Crawl Budget: Too many redirects can consume crawl budget, potentially impacting the indexing of your site.
Mobile-First Indexing: Ensure redirects are correctly set up for mobile versions of your site, as Google predominantly uses mobile-first indexing.
Redirecting for HTTPS: When moving a site from HTTP to HTTPS, ensure all URLs are correctly redirected to their secure versions.

HTTP Status Codes
What are they?
HTTP status codes are standardized responses from a web server indicating the result of a requested action. These codes are part of the HTTP (Hypertext Transfer Protocol) response sent to the browser or requesting client.
What is the functionality?
These codes inform the client (usually a web browser or a crawler) about the status of its request to access a web page. They indicate whether a request has been successfully processed, redirected, encountered an error, or failed.
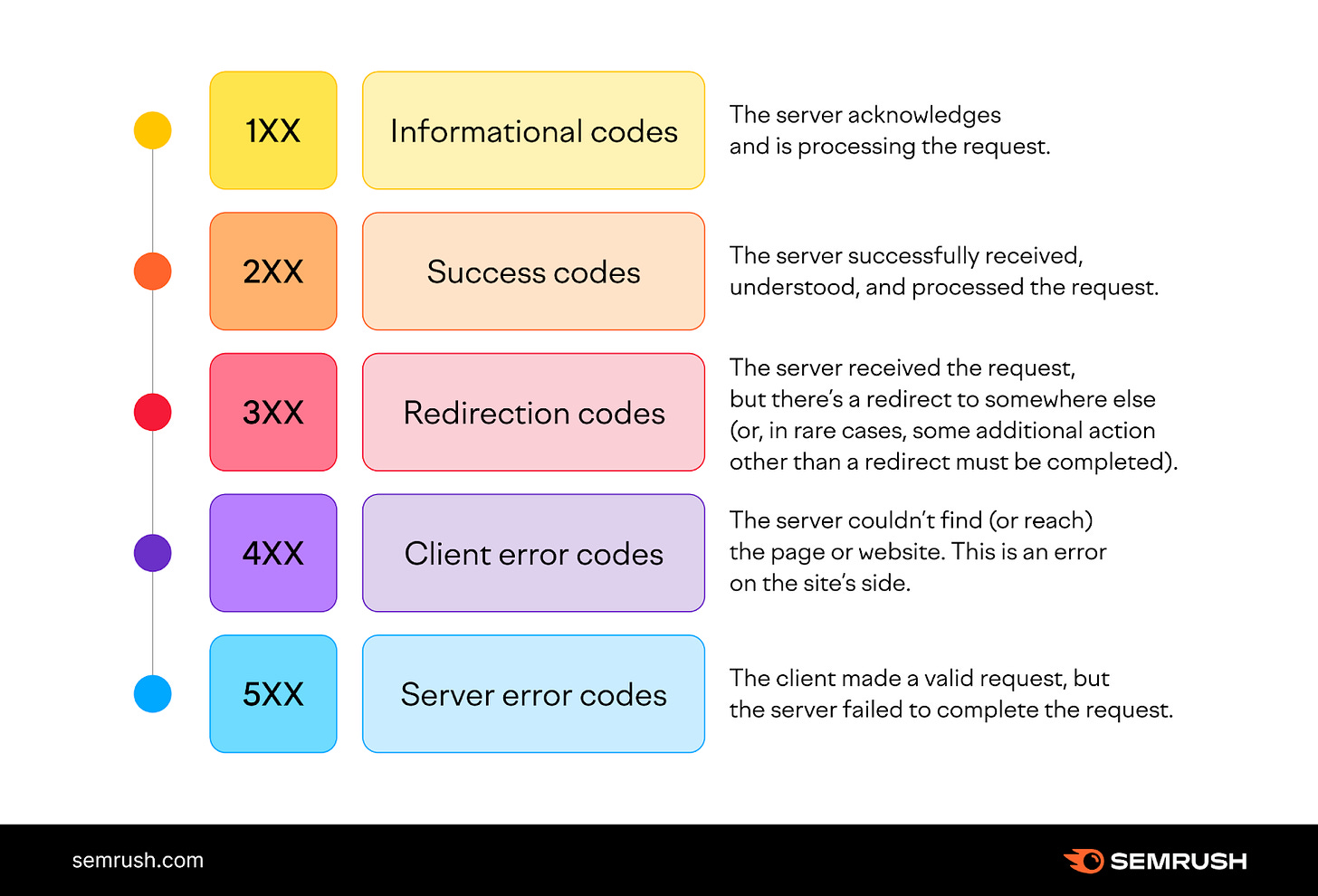
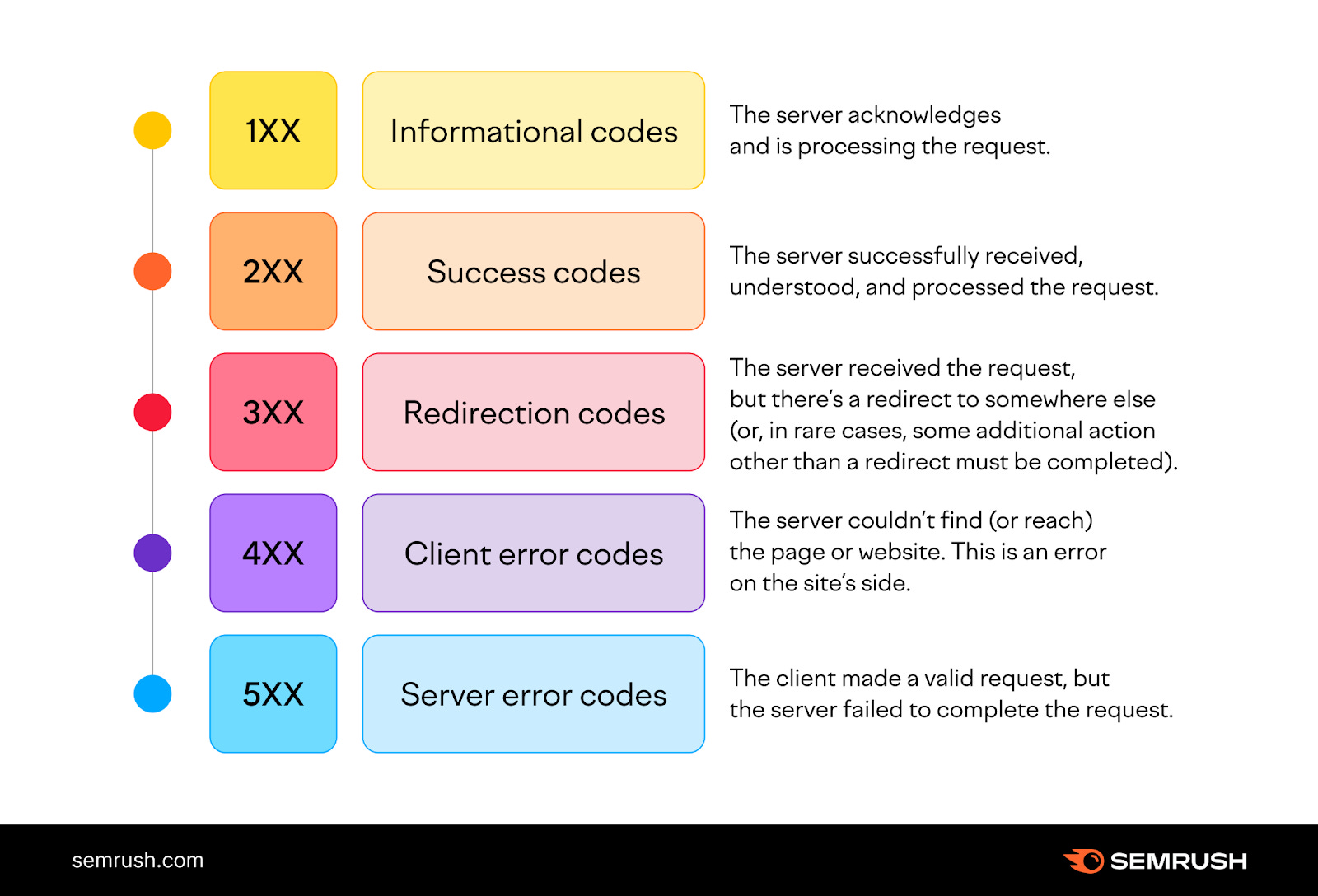
Type of Status Codes
1xx (Informational): Indicate a provisional response, requiring requestor to continue the action.
2xx (Success): Confirm that the request was received, understood, and accepted.
3xx (Redirection): Indicate that further action needs to be taken to complete the request, often used for URL redirection.
4xx (Client Error): Show errors on the client's side, like the well-known 404 Not Found.
5xx (Server Error): Indicate problems with the server fulfilling the request, such as a 500 Internal Server Error.
Where are they located?
These codes are not located in a file on a website like robots.txt or sitemap.xml. They are part of the HTTP response header, which is sent from the server to the client (browser or crawler) when a resource (like a web page) is requested.
How important are they?
Understanding and properly handling these status codes is essential for website maintenance, user experience, and SEO. Correctly interpreting and responding to these codes can improve site reliability and search engine ranking.
Tips for handling them
Regularly check for 4xx and 5xx errors on your website using tools like Google Search Console.
Set up appropriate 301 redirects for permanently moved pages to maintain SEO value.
Customize your 404 error page to guide users back to your site's useful content.
Monitor server logs for 5xx errors and resolve any server-side issues promptly.
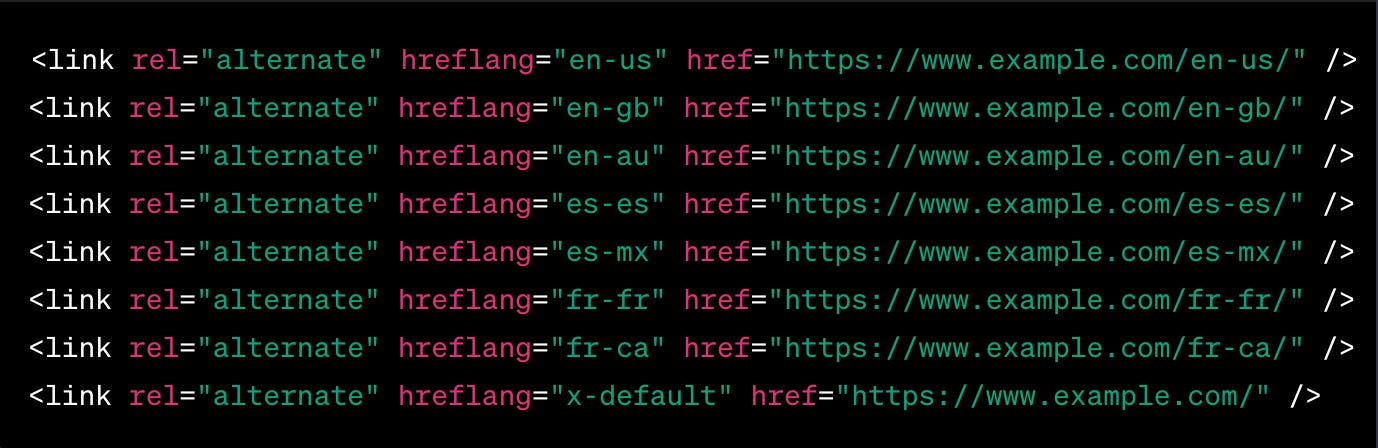
Localisation tags ( hreflang )
What are they?
Localisation tags, often referred to as hreflang tags, are HTML attributes used to tell search engines about the language and geographical targeting of a webpage. They help in serving the correct language or regional URL in search results.
What is the functionality?
These tags inform search engines which version of a page to show in search results based on the user's language and region. For example, if you have different versions of a page in English and Spanish, hreflang tags help search engines display the appropriate version to users based on their settings or location.
Where are they located?
Localisation tags are placed in the
<head>section of the HTML of a webpage, or they can be added in the HTTP headers. Each page that has language or region-specific versions should include these tags pointing to the corresponding versions.
How important are they?
They are crucial for websites that target audiences in multiple languages or regions. Proper use ensures users are directed to the content most relevant to their language and location, improving user experience and potentially increasing engagement and conversion rates.
Tips for implementing them
Use the correct language and region codes (e.g., en-GB for English, Great Britain).
Ensure that the content matches the language and region specified by the tag.
Avoid using these tags if your site's content is the same across different language versions.
Use self-referencing hreflang tags: each page should include a tag for itself along with tags for other language or regional versions.
Core web vitals
Overview
Core Web Vitals are a set of specific factors that Google considers important in a webpage's overall user experience. They are part of Google's "page experience" signals used to measure user satisfaction.

What are the key components?
LCP ( or Largest Contentful Paint )
It measures the loading performance of a webpage.
Aim to bring this metric to 2.5 seconds of when the page first starts loading.
On a the technical side, LCP focus on the render time of the largest image or text block visible within the viewport.
FID ( or First Input Delay )
It measures the interactivity
Ideally, you should target to achieve less than 100 milliseconds.
On the technical side, FID captures the time from a when a user first interacts with your site ( button click etc. ) to the time when the browser responds to the interaction.
CLS ( or Cumulative Layout Shift )
Measure the visual stability
You should try to maintain a score of less than 0.1
On the technical side, CLS quantifies the amount of unexpected layout shift of visible page content.
How important are they for SEO?
Core Web Vitals are one of top 3 ranking factors for the Google algorithm. They directly impact a site search ranking, reflecting its emphasis on user experience.
Implementation Tips
Regularly use tools like Google PageSpeed Insights or Lighthouse to measure and monitor these metrics. The data there is easy to pick up and display to an engineering team for them to prioritize work.
Optimize images and serve them in next-gen formats for better LCP.
Minimize or defer JavaScript for better FID.
Ensure stable loading of elements to avoid CLS, such as allocating size attributes for images and embeds.
Continuously monitor these metrics through Google Search Console's Core Web Vitals report.
Stay updated with Google's guidelines, as these metrics can evolve over time ( highly recommended ).

Structure data & Schema markup
Overview
Structured Data and Schema Markup are techniques used to annotate and organize the information on web pages, making it easier for search engines to understand the content and context of the pages.
Key Components
Structure Data
It's a standardised format for providing information about a page and classifying the page content.
You can implement it by using various syntaxes like JSON-LD, Microdata, or RDFa.
Helps search engines understand the content of a page and provide richer search results (like rich snippets).
Ex. 1
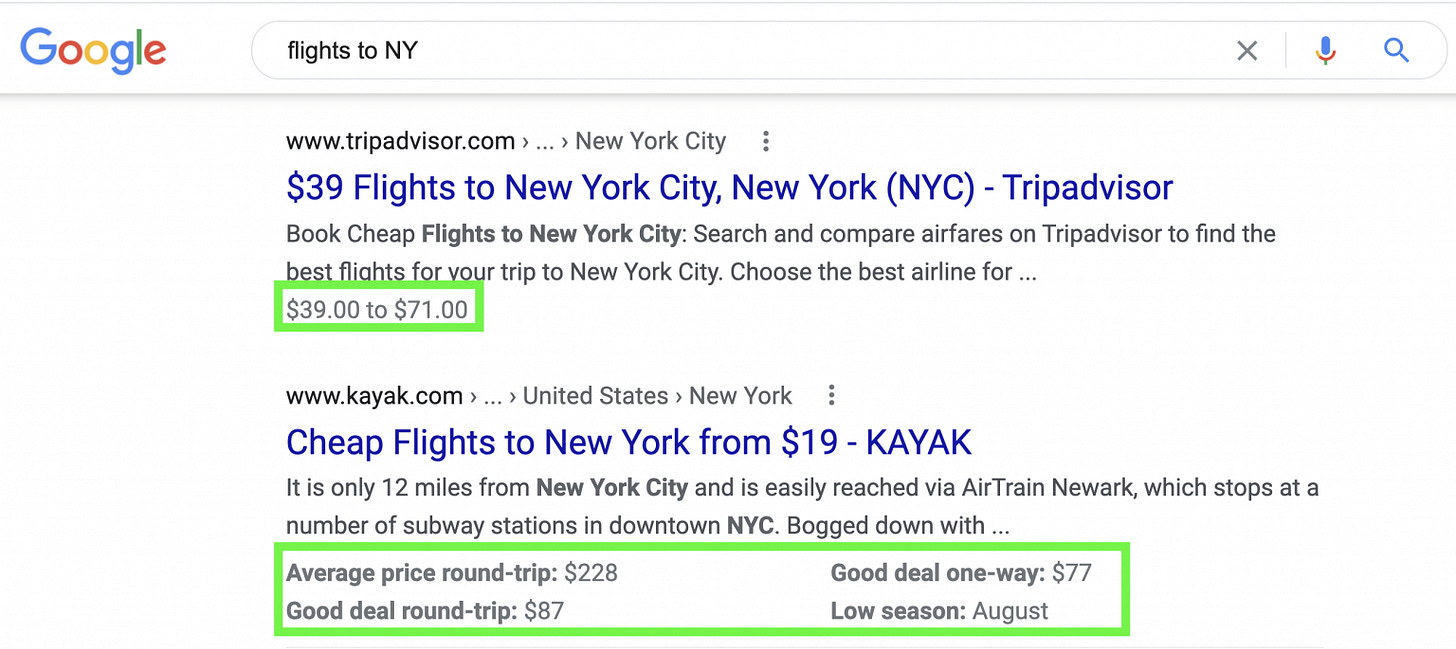
Ex. 2
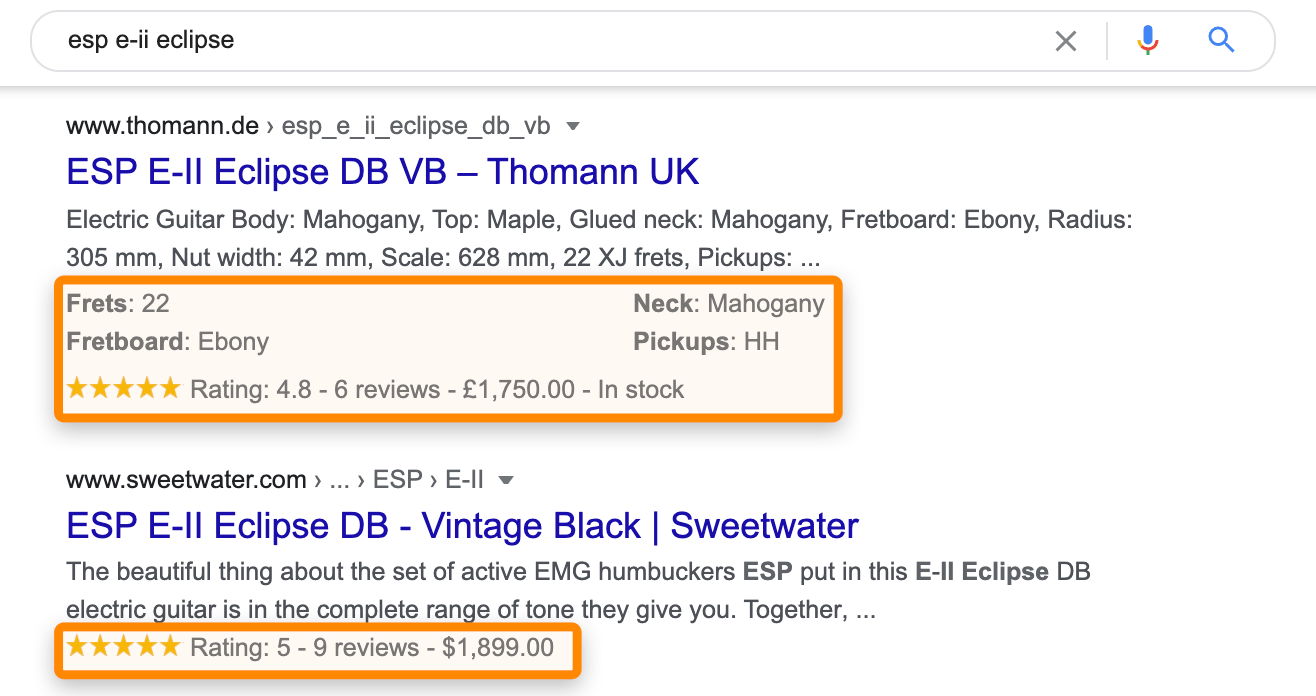
Image Source: Ahrefs
Schema Markup
A collection of specific data vocabularies that you can use to mark up your content in ways recognized by major search engines.
There are many types of schemas you can use like: articles, local business, events, FAQs, products and more.
The main goals is to enhances the display of search engine results, improving visibility and click-through rates.
You can test here: https://developers.google.com/search/docs/appearance/structured-data
Getting started with Schema:

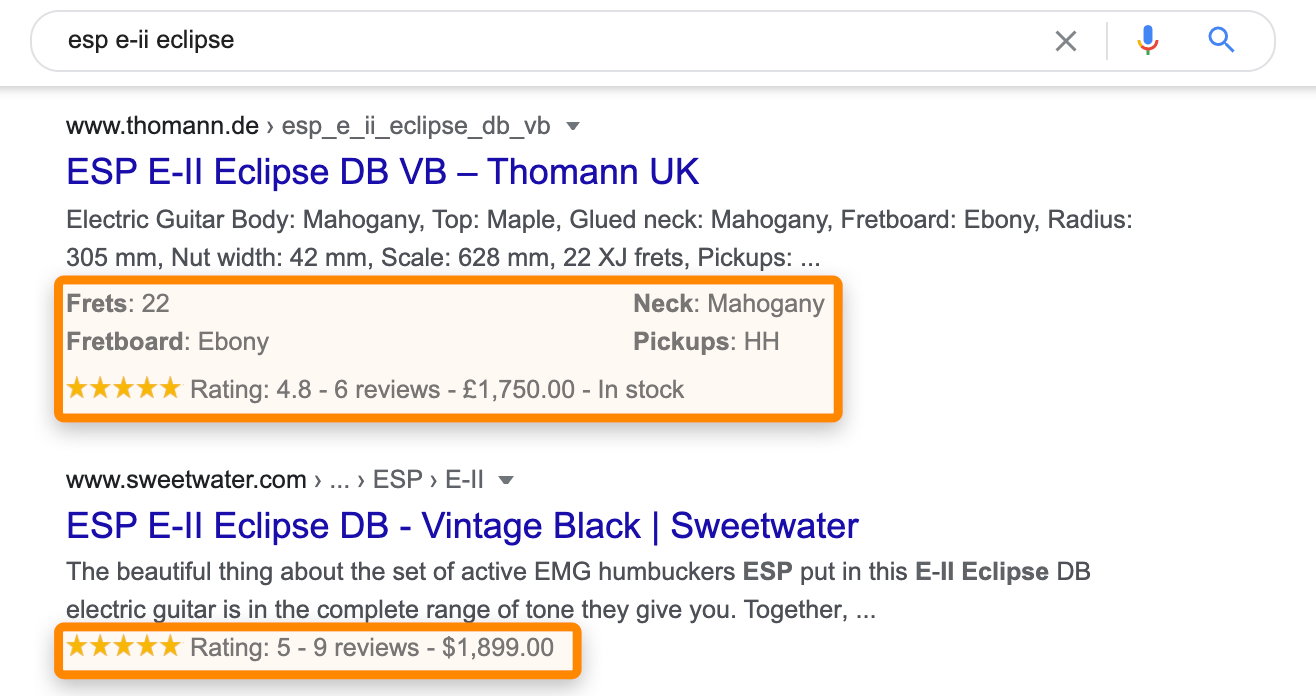
What mistakes to avoid when working on Technical SEO?
The last point of this article will focus on the high-level mistakes to avoid when working on Technical SEO. The idea is to zoom out from the individual components discussed above.
Lacking a holistic SEO strategy: Ensure Technical SEO integrates with overall SEO strategies, including content and off-page SEO, for a unified approach.
Not prioritising user experience: Technical SEO should always enhance, not detract from, the user experience. User engagement metrics are increasingly important for SEO.
Failing to keep up with search engine algorithm updates: Stay informed about the latest search engine algorithm changes. What worked yesterday might not be effective today ( VERY IMPORTANT POINT ).
Overlooking website scalability and flexibility: Design your website’s technical infrastructure to be scalable and adaptable to future changes in content, traffic, and SEO best practices. Especially true, with websites with tens of thousands of URLs.
Poor stakeholder integration: Technical SEO is a team collaboration effort, which can drain significant product & tech resources. Be sure to create a clear understand of the process and impact with other team members.
As a closing thought, I would say that throughout my career, working on Technical SEO is hard, but it's the most important lever of any long-term SEO strategy. I hope this guide will help any team or individual contributor get a better understanding of the concept of Technical SEO and its components. It might sound overwhelming at first and a bit hard to understand and collaborate with your internal teams, but in the long run, you will benefit the most from having a healthier website.